Initial Results
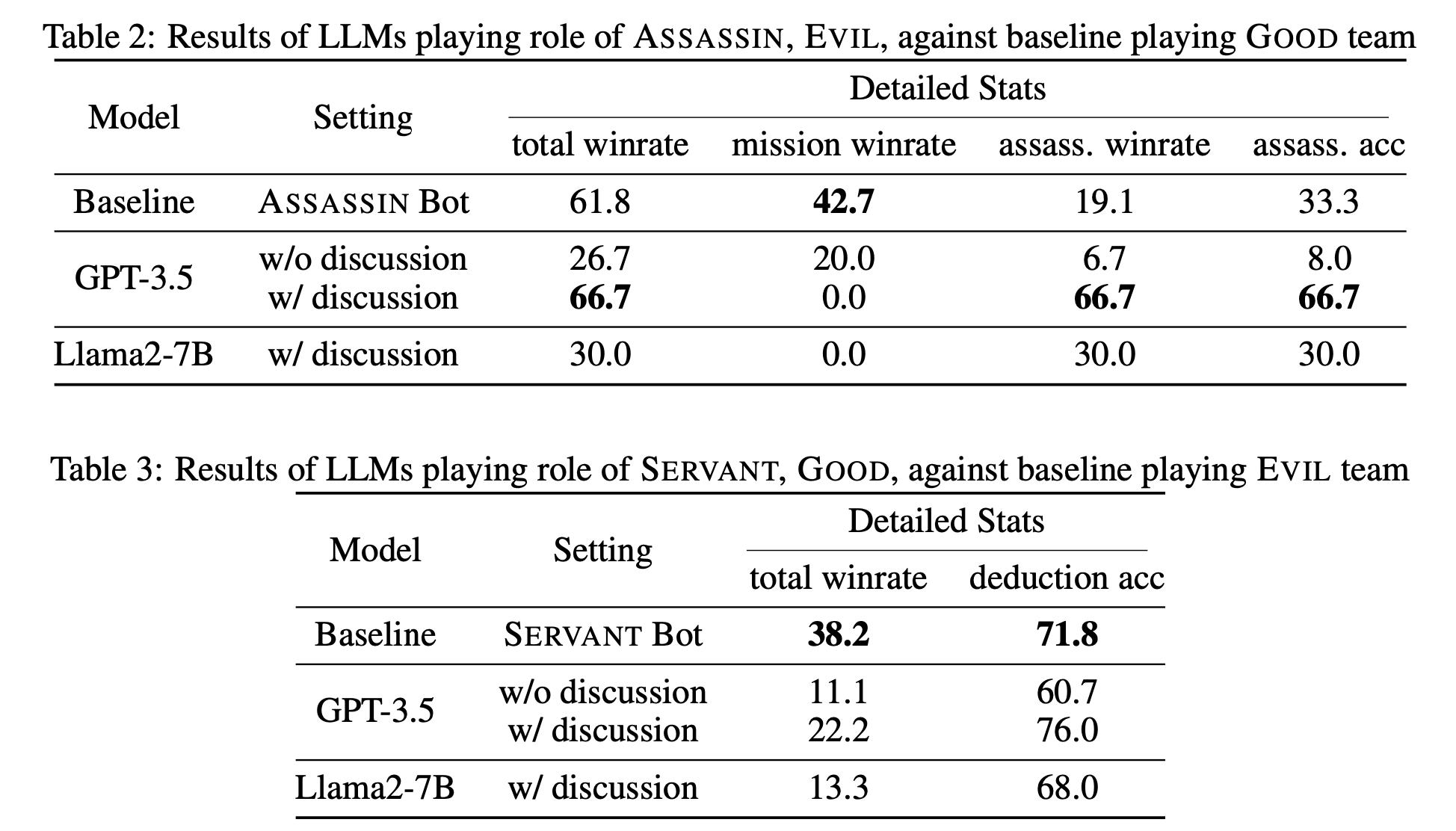
LLMs Play Against Baseline Bots
Here are the results of LLMs playing against baseline bots.
Multi-LLMs Self-Play
We also let LLMs playing against each other. Evil has an 8:2 advantage over Good, which is similar to the stats of rookie human players! Here are also some examples of discussion under this setting.


Initial Results with New Codebase
We have updated our code with a new version of AgentBench (v0.2). Here are the results of LLMs playing against baseline bots.
{
"total": 20,
"validation": {
"running": 0.0,
"completed": 0.95,
"agent context limit": 0.0,
"agent validation failed": 0.05,
},
"custom": {
"Win rate of Player 0": 0.15,
"Avg deduction acc of Player 0": 0.5399999999999998,
"Valid number of games": 19,
"Average time cost": "1:58"
}
}
Results of GPT-3.5-turbo🤖 playing against rule-based bots
{
"total": 20,
"validation": {
"running": 0.0,
"completed": 1.0,
"agent context limit": 0.0,
"agent validation failed": 0.0,
},
"custom": {
"Win rate of Player 0": 0.2,
"Avg deduction acc of Player 0": 0.55,
"Valid number of games": 20,
"Average time cost": "10:36"
}
}